Jamworks & GPT 4 Vision – The future of AI in Education
Published:
Amirah Khan

GPT-4 with Vision is an advanced model that brings the power of “sight” to generative AI tools. This exciting development allows the model to process and understand visual inputs. By merging visual capabilities with existing text-based features, this model has great potential, especially for improving accessibility.
Jamworks plans to leverage the power of GPT-4 to expand its offering to students. As an AI-powered note taking and study tool, Jamworks intends to remain a state-of-the-art educational application with accessibility at its core.
In this blog, we’ll explore GPT-4 vision in more depth and how this model can enhance Jamworks’ features for all students.
What is GPT-4 Vision?
GPT-4 with Vision (GPT-4V) expands and builds upon the capabilities of GPT-4 to offer multimodal features. That is, this new model can work with more than one type of data, to provide an enhanced generative AI experience. ChatGPT, which is powered by the GPT models, can now go beyond text-based information to process visual inputs.
Users can upload images, such as photos, screenshots, and documents for GPT-4 vision to process, understand, and act upon. The model can answer questions about the image, perform actions based on user prompts, and offer visual analysis.
Let’s take a further look at the model’s key capabilities.
Key Capabilities of GPT-4 Vision
Identify objects in an image and provide information about them
Decipher handwritten or printed text present in an image
Generate rich descriptions or summaries of the visual content
Answer questions about the image, allowing users to seek more context and detail
Interpret and analyse data from visual charts, graphs, or other visual data formats
Act upon user requests that feature visual information
For example, a prompt could be “Can you write a response to this letter?” with an image of a printed or handwritten letter. Or, “Write me a bullet point summary about X” with an image of a graph. This highlights the power that multimodal models can have in providing an enhanced user experience.
Use Cases for GPT-4 Vision
AI-powered Assistance for the Visually Impaired
Be My AI is an app that offers digital assistance to blind or low-vision individuals using GPT-4 vision. Users can upload images to receive detailed descriptions of the visual content. They can ask questions about the image, and seek out further details and context. This app, offered by Be My Eyes, highlights the value of GPT-4 vision for improving accessibility.
Be My Eyes has extended its AI offering by deploying Be My AI as a customer service tool. Blind or low-vision customers can now access AI-powered visual customer service. Microsoft’s Disability Answer Desk implemented this for their customers and found a 90% success rate.
Data Analysis and Mathematics
GPT-4 vision can interpret and analyse visual forms of data, including charts, graphs, and tables. This opens up a range of possibilities for academics, digital marketers, and anyone who wants a quick data summary. The model can extract and interpret the data before transforming it into an output of the user’s choice.
Others have found GPT-4 vision can understand and explain mathematical formulae. This can be a useful starting point for understanding how to solve complex problems. For more simple maths, GPT-4 vision can make sense of and analyse someone’s budget. Another user found the model could turn a screenshot of a mathematical formula into Python code!
Possibilities of User Prompts
Visual information when paired with creative user prompts can offer a range of use cases. Here are some other ways the model can be used:
Generate text transcription from handwritten documents
Analyse a website design and provide feedback to improve UX and accessibility
Provide key facts about your scenic environment
Create inventory lists based on the items in an image
Write up product descriptions
Prepare a response to handwritten or printed letters and notes
Offer visual study assistance to students and self-learners
Jamworks and GPT-4 Vision for Students
Jamworks plans to enhance its AI-powered note taking and study tool with GPT-4 vision. Students who are blind or low vision can benefit from accessible learning experiences with AI. Visual learning assistance can benefit all students by opening up new ways to learn independently.
Students use Jamworks to capture and transform their lecture content into accessible notes and study materials. Jamworks automatically breaks the content down into highlights, smart summaries, and multimedia notes. To aid learning, this tool also offers AI-powered flashcard quizzes and JamAI, a personalised tutor chatbot.
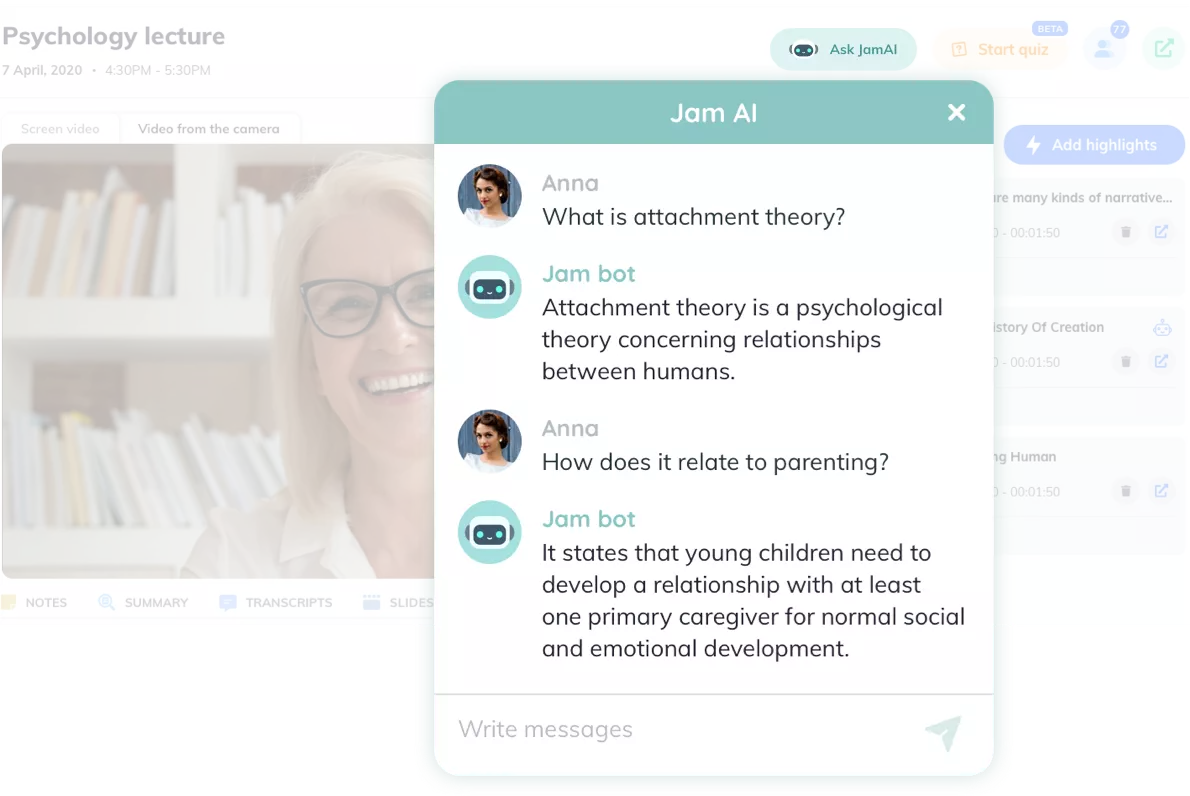
Using GPT-4 vision, Jamworks will allow students to:
Ask questions about their lecture slides and content from their video lecture recordings
Upload images to have JamAI analyse, explain, and answer questions about
Access detailed descriptions of visual information to improve understanding
Accessibility is a core feature of Jamworks and visual study assistance will enhance their offerings. As demonstrated by Be My AI, visual assistance can hold incredible value for the visually impaired. Jamworks can offer more personalised, accessible learning support that allows students to explore their study materials with flexibility and independence.
Imagine if students could:
Upload pictures of graphs, illustrations, or handwritten notes to get more insight
Ask for feedback on their visual content
Generate visual descriptions, summaries, and interpretations of what they are looking at
Jamworks aims to make this a possibility and remain an advanced AI tool for accessible learning.
Book a call if you would like to discuss Jamworks and GPT 4 Vision in more detail.


